If you’re a digital marketer you’ve undoubtedly heard of and probably used Slideshare at least once. The website owned by LinkedIn (and now Microsoft) is a popular place for marketing thought leaders to share slide decks of their work, research, and conference presentations. Every SEO I know has a Slideshare account including big names like Rand Fishkin as do tech heavyweights like Tim O’Reily.
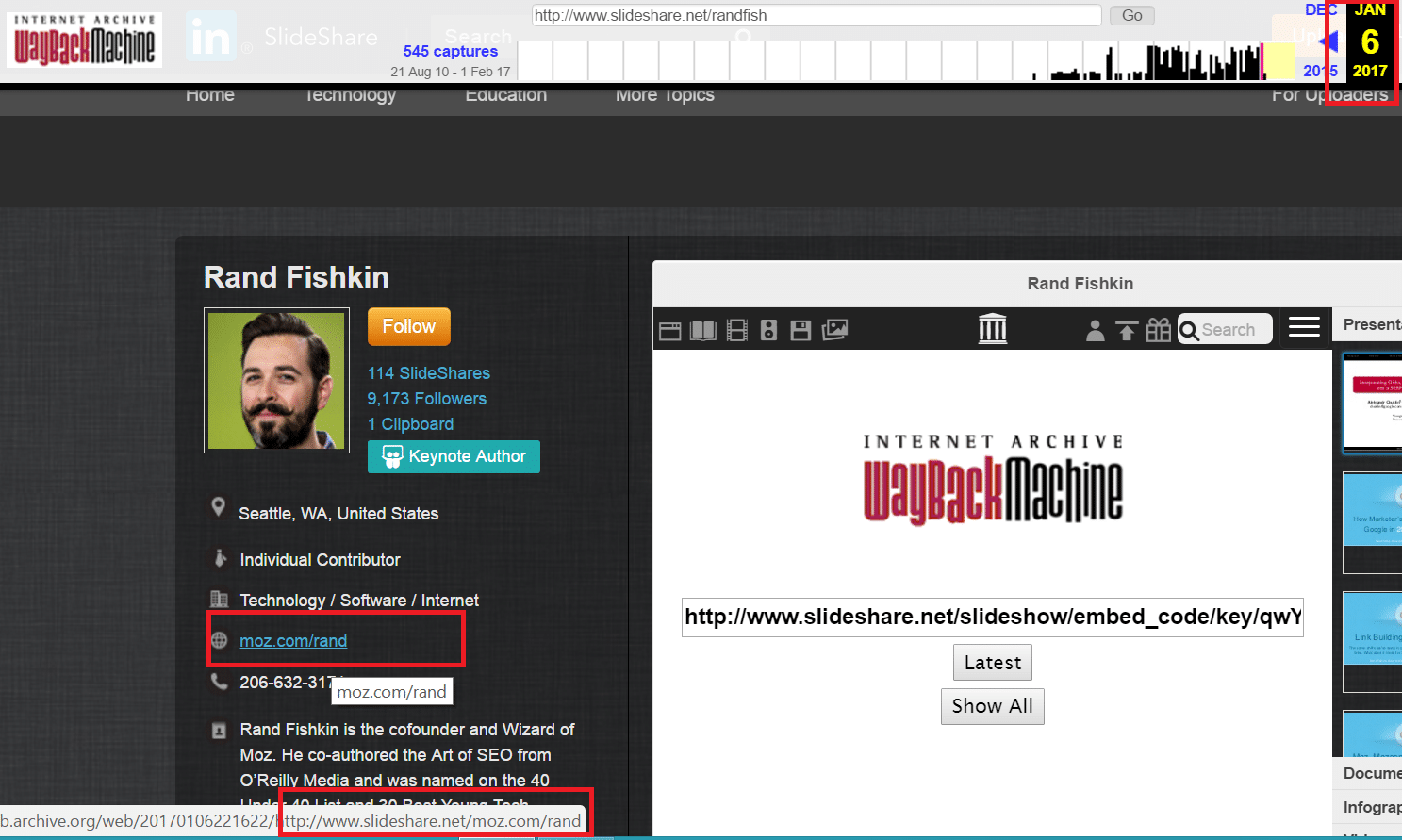
With all of this knowledge being hosted and being owned by Microsoft, effectively the #2 search company in the USA, I would think that Slideshare would do pretty well with technical Search Engine Optimization techniques, I would be wrong. It would appear from Archive.org’s caches of Rand’s and Tim’s profiles that Slideshare made a change to their profile pages around January 6th, 2017. This change rendered the website link in the Slideshare profile useless and began creating hundreds and thousands of thin pages on the Slideshare website itself.
This bug could have an impact on Google’s rankings both in how Slideshare itself ranks due to a bloated index filled with lots of thin pages and in how Google might rank the sites with profile links (though maybe to a much lesser degree). We’ll examine these two in just a moment.
What Caused This SEO Error?
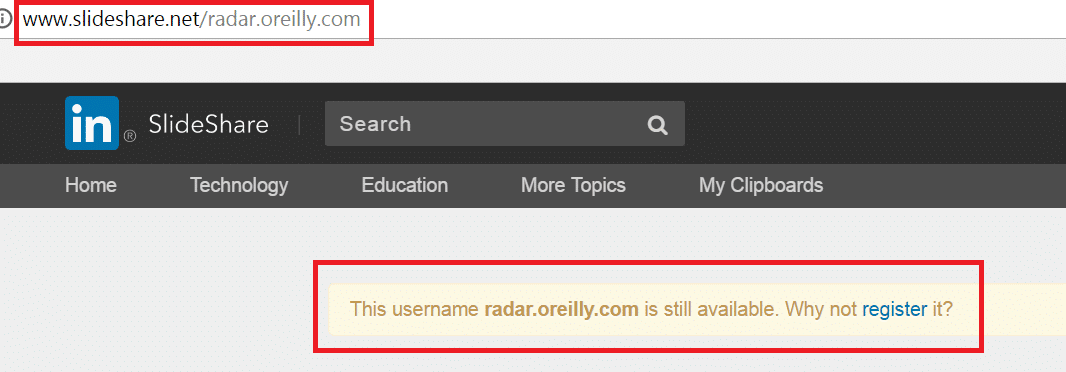
It appears this is all probably a code error. Often times in a CMS if the HTTP is not included in a url you’ll see links adopting relative path instead of absolute path. Meaning that in the code the website CMS appears to strip out the HTTP:// and only using the domain portion. Interestingly enough if the website using WWW. Slideshare appears to create the domain inside of the users portfolio. For example with mine the path Slideshare is using is /joeyoungblood/www.joeyoungblood.com but for Tim it is /radar.oreilly.com and for Rand it is /moz.com/rand. I attempted to fix this by including the HTTP:// when putting in my website information, but Slideshare stripped it out. So the CMS is stripping out user entered HTTP info likely expecting to re-add it later on to keep everything uniform on the backend. As you can see in the below code the platform never re-adds the HTTP:// and browsers then assume it’s a relative path with Slideshare.net as the root.

Is This Hurting Slideshare.net’s SEO?
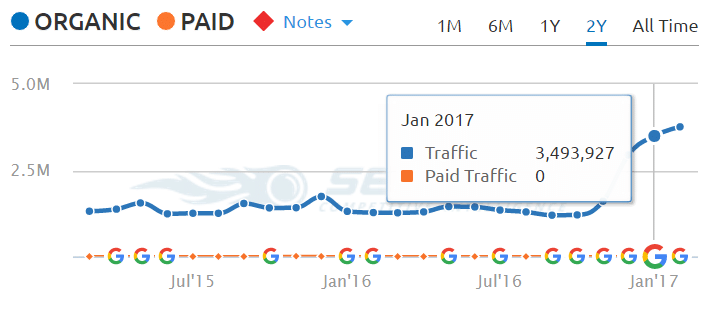
Probably. The header code output from these pages is very interesting. Slideshare’s platform appears to know the pages do not exist and tries to 301 redirect them, but it has no where to send them to, and ends up 301 redirecting them back to the same URL – this time giving a 404 page not found error code. This should burn up Slideshare’s crawl budget and lead to some lower rankings and traffic. However, if SEM Rush’s data is to be believed it hasn’t hurt that much as Slideshare shows nearly double Organic Traffic Year over Year going from 1.30 million visitors to 3.49 million visitors. Granted the site could see less traffic from Google and more from Bing after the purchase by Microsoft.
Is This Hurting Your SEO?
That’s a more iffy question. Since this link appears on your profile page and is set to nofollow this would all be based on how Google is treating the links from Slideshare. If you’re in a small niche or market that is competitive or everyone has a low volume of links, losing this one nofollow link could be the straw that drops you below a competitor. Larger sites like the above mentioned Moz and Oreilly are probably unaffected. My organic traffic actually saw an increase after January 6th of this year, so if it did impact me it wasn’t much.
It is more likely that this could be hurting your referral traffic if you use Slideshare as a traffic source or lead generation source. Check your own Analytics logs under refers and see how you’re impacted.
How Would You Fix This SEO Fail?
Well if you ever run into this with your own CMS the good news is it’s likely not a difficult fix. Tell your developer about the problem and that it appears your posting external links using relative path versus the absolute path which is causing some headaches. They should be able to diagnose the problem quickly and in most cases (even with Agile based dev teams) can publish the fix within a day or two.
Once you have the broken links repaired you’ll need to do some damage cleanup. In this instance the broken links are not appearing in one specific directory so controlling them with Robots.txt would be difficult. It might be possible to export data from a database and use that to set htaccess up using Regex to either give each one of these URLs a 410 Gone response or 301 redirect them back to the root domain. If that’s out of your league you could simply export your 404 errors in Google Search Console, drop them into Excel, and generate a long list of one-to-one 301 redirects that way. You’ll also want to make sure these new fake URLs didn’t get inserted into any Sitemap.xml files. I tried looking at this for Slideshare but they have a lot of sitemap files (335 at last check) and I decided to not spend my time there.
How To Avoid Technical SEO Issues Like This One?
When the development team has changes on their dev / qa / staging server always check at least one sample page of a template for broken links or external links that are suddenly internal. This problem is fairly common and should be caught in a QA stage before going live. There are a few ways to do this automatically, but a manual check should work fine in most cases. If you try and use a web-based SaaS tool to crawl the development server and are able to, that’s an entirely different problem as it shouldn’t be possible for external tools to crawl a dev site.